

Azure には Azure Resource Health(Azure リソース正常性)という、
「自分がデプロイしたリソースの状態(正常性など)を検知して通知するサービス」があります。
これを利用すると仮想マシンを停止した場合などにもリソースの状態変化として通知することができ、自分のリソースの正常性を知ることができます。
今回は、Azure Resource Health(Azure リソース正常性)を設定し、仮想マシンを停止させてメール通知させてみました。
似たようなサービスとして Azure Service Health(Azure サービス正常性)がありますが、
違いをまとめると以下の通りとなります。
- Azure Resource Health:基盤障害含めて自分のリソースの正常性に影響が出た場合に通知される
- Azure Service Health:Azure 基盤障害などが発生しサービス自体に影響が出た場合に通知される
Azure Service Health(Azure サービス正常性)の設定については以下の記事でも紹介していますので参考にしてください。

Azure Resource Healthを設定する
早速設定していきます。
Resource Health アラート作成画面までの遷移
・Azureポータル上から AzureMonitor を開きます。
画面上部の検索を利用してもいいですし、左上の三本線のタブを開いて選択することができます。
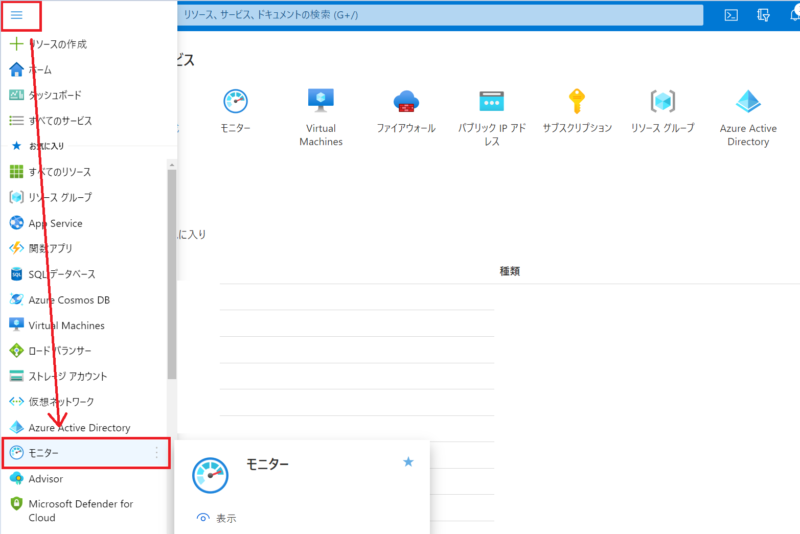
・AzureMonitor のページから「Service Health」を開きます。
※ここまでは Service Health の設定と一緒です。
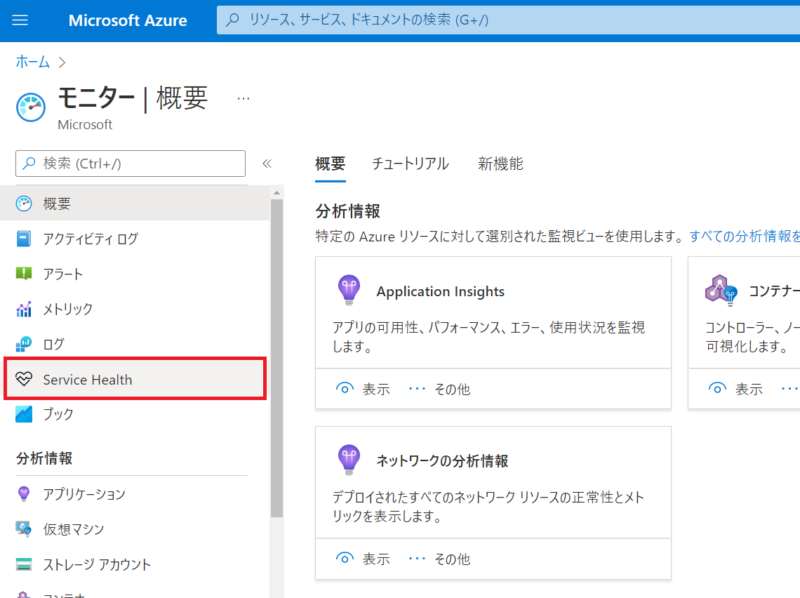
・「Service Health(サービス正常性)」専用のページに変わるので
「リソース正常性」をクリックし、「リソース正常性アラートの追加」をクリックします。
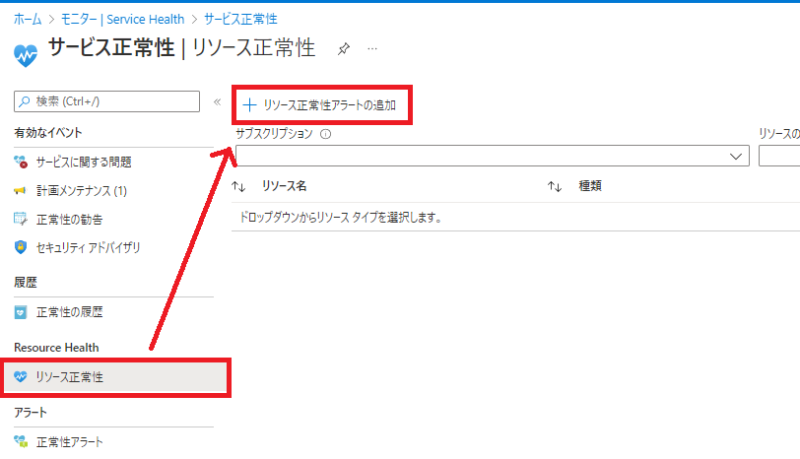
Resource Health アラート作成
ここから具体的にアラートの中身を作成していきます。
「アラートの対象」の設定
まず「アラートの対象」部分を定義していきます。
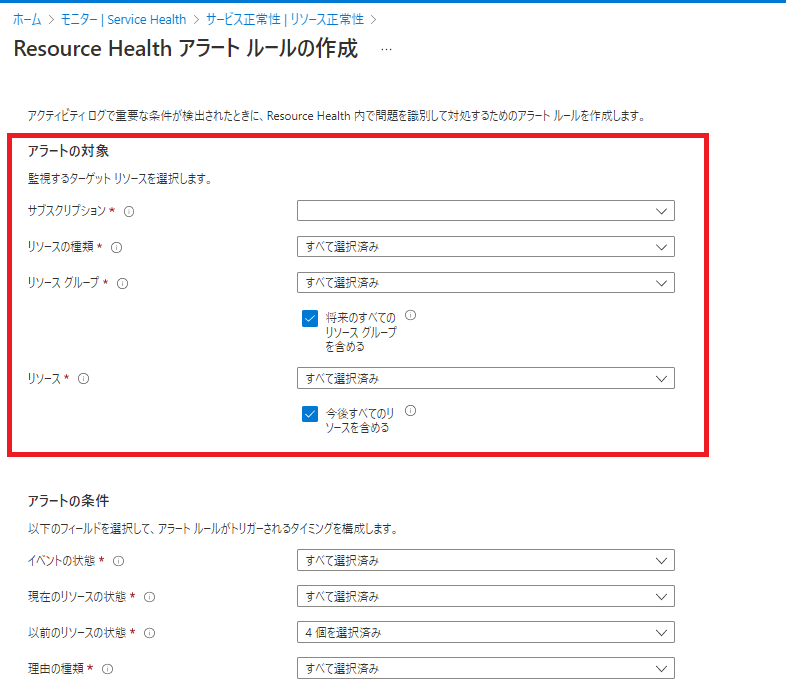
・「サブスクリプション」
Resource Health アラートを設定するサブスクリプションを選択してください。
迷うことはないと思うので詳しい説明は割愛します。
・「リソースの種類」
プルダウンから正常性の検知対象としたいサービスを選択します。
デフォルトではすべてのサービスにチェックが付いていますが、今回は「Virtual Machine(仮想マシン)」のみを選択します。
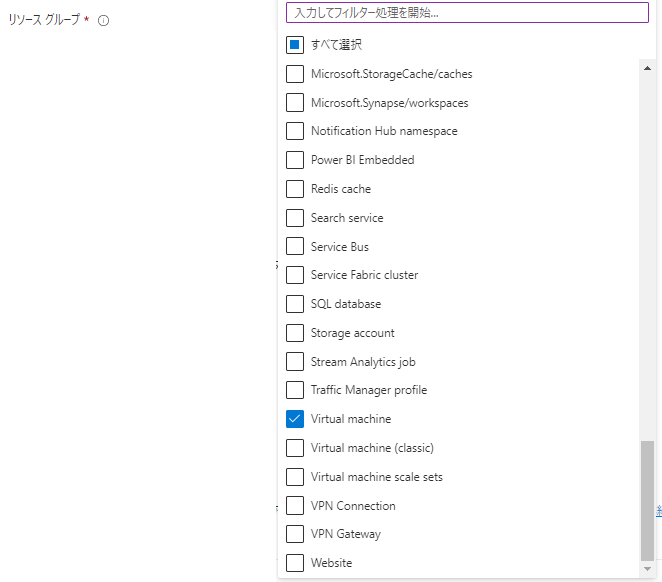
・「リソースグループ」
リソース正常性を設定したいリソース(今回は仮想マシン)が含まれるリソースグループを選択します。
全てのリソースグループを選択する場合にはさらに「将来のすべてのリソース グループを含める」かどうかを選択できます。

今回は1つのリソースグループを選択します。
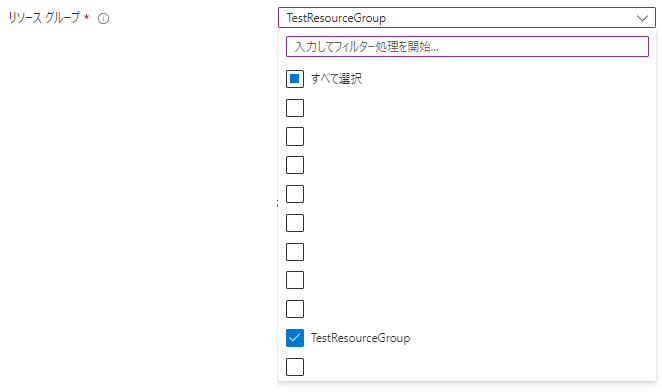
・「リソース」
リソースグループ内のリソース正常性を設定したいリソース(今回は仮想マシン)を選択します。
全てのリソースを選択する場合にはさらに「今後すべてのリソースを含める」かどうかを選択できます。

今回は1つの仮想マシンを選択しますが、リソースグループ内に1つしかないので必然的に「すべて選択」となります。
また、せっかくなので「今後すべてのリソースを含める」にもチェックを入れておきます。

「アラートの条件」の設定
「アラートの条件」を定義していきます。
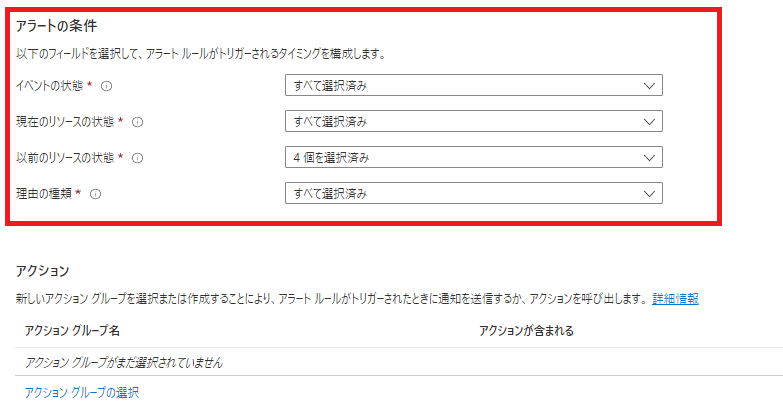
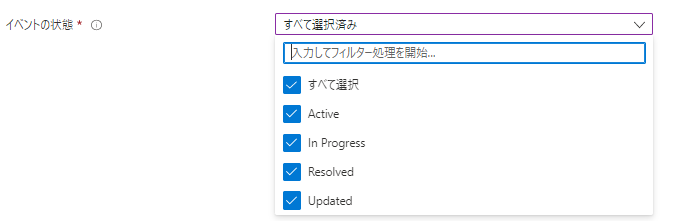
・「イベントの状態」
「どんなイベントの状態を通知するのか?」を選択します。
以下の4つの状態がAzureでは定義されています。
- Active:イベント発生時
- In Progress:イベントが進行中であるとき
- Resolved:イベントが解決したとき
- Updated:イベントが更新されたとき
今回は、それぞれどのような通知が来るのかを確認してみたいので、すべて選択しておきます。
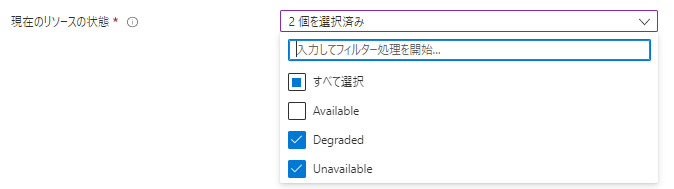
・「現在のリソースの状態」
次にリソースがどのような状態になったら通知するのか?という「リソース状態の変化後の状態」を選択します。
以下の3つの状態がAzureでは定義されています。
- Available:使用可能な状態
- Degraded:低下状態
- Unavailable:使用不可な状態
今回は、仮想マシンが利用できなくなった場合に通知をさせたいので、
「リソース状態の変化後の状態」としては「Degraded」「Unavailable」の2つを選択します。
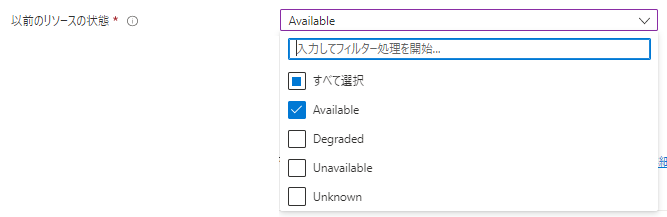
・「以前のリソースの状態」
次にリソースがどのような状態のものを対象とするのか?という「リソース状態の変化前の状態」ときに通知するのか?」を選択します。
以下の4つの状態がAzureでは定義されています。
※「現在のリソースの状態」の選択肢から「Unknown」が追加されています。
- Available:使用可能な状態
- Degraded:低下状態
- Unavailable:使用不可な状態
- Unknown:不明な状態
今回は、仮想マシンが利用できなくなった場合に通知をさせたいので、
「リソース状態の変化前の状態」としては「Available」のみを選択します。
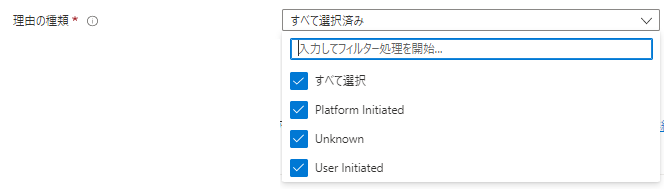
・「理由の種類」
さいごに「どんな原因で引き起こされたものを通知対象にするのか?」を選択します。
以下の3つがAzureでは定義されています。
- Platform Initiated:Azure基盤が原因で発生したイベント(基盤障害など)
- Unknown:原因が不明なイベント
- User Initiated:ユーザー起因で発生したイベント(ユーザによるリソース停止など)
今回は、すべて選択しておきます。
「アクション」の設定
次に「アクション」部分を定義していきます。
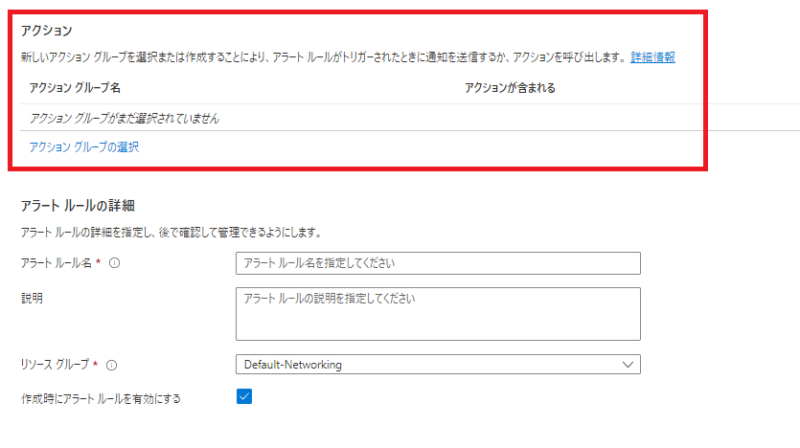
今回は事前に作成してあるアクショングループを選択します。
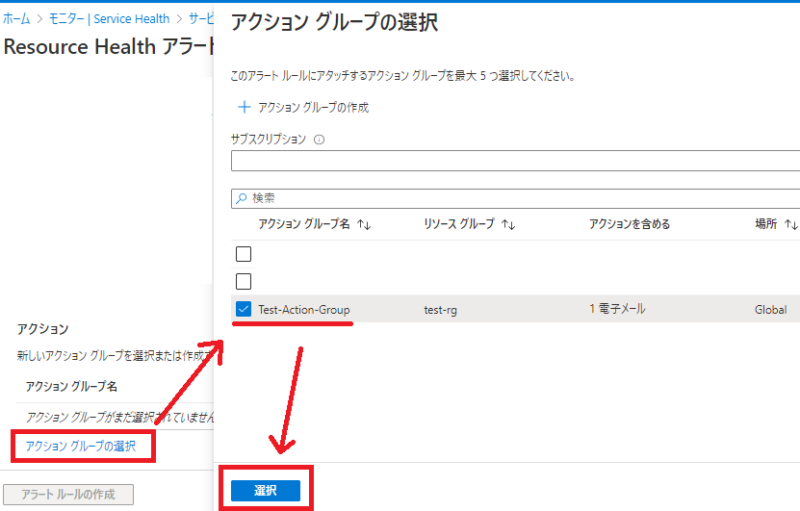
アクショングループの作成方法は以下の記事にまとめてありますので必要であれば参考にしてください。
「アラート ルールの詳細」の設定
さいごに「アラートルールの詳細」を定義します。
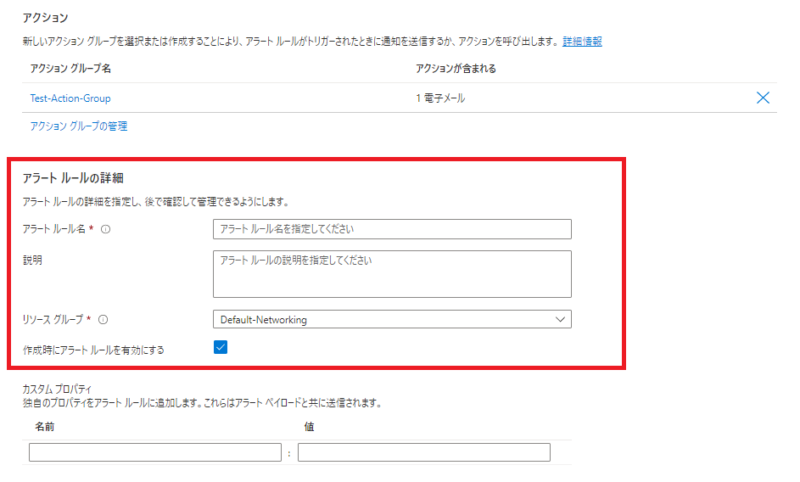
ここでは「アラートルール名」や「リソースグループ」を選択します。
※ここも迷うことはないと思うので細かい説明は割愛します。
さいごに「アラートルールの作成」をクリックして作成完了です。
作成後に作成完了通知が来れば作成完了です。
実際に仮想マシンを再起動してメール通知させてみる
実際に仮想マシンを再起動してどのような通知が来るのかを見てみます。
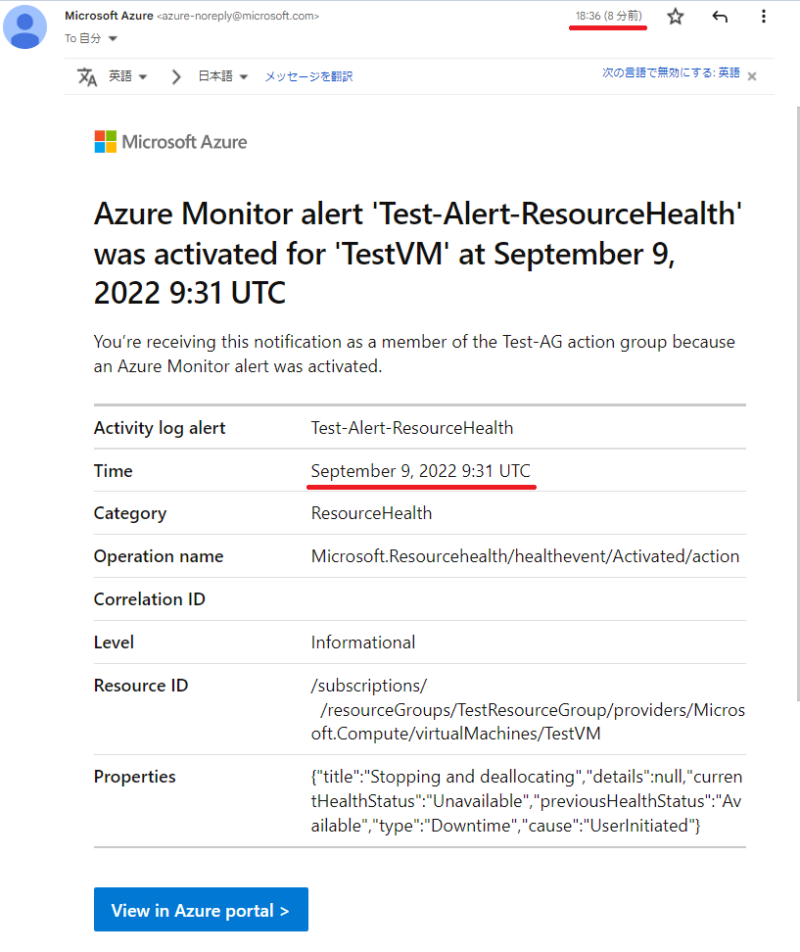
通知は以下の通りきました。
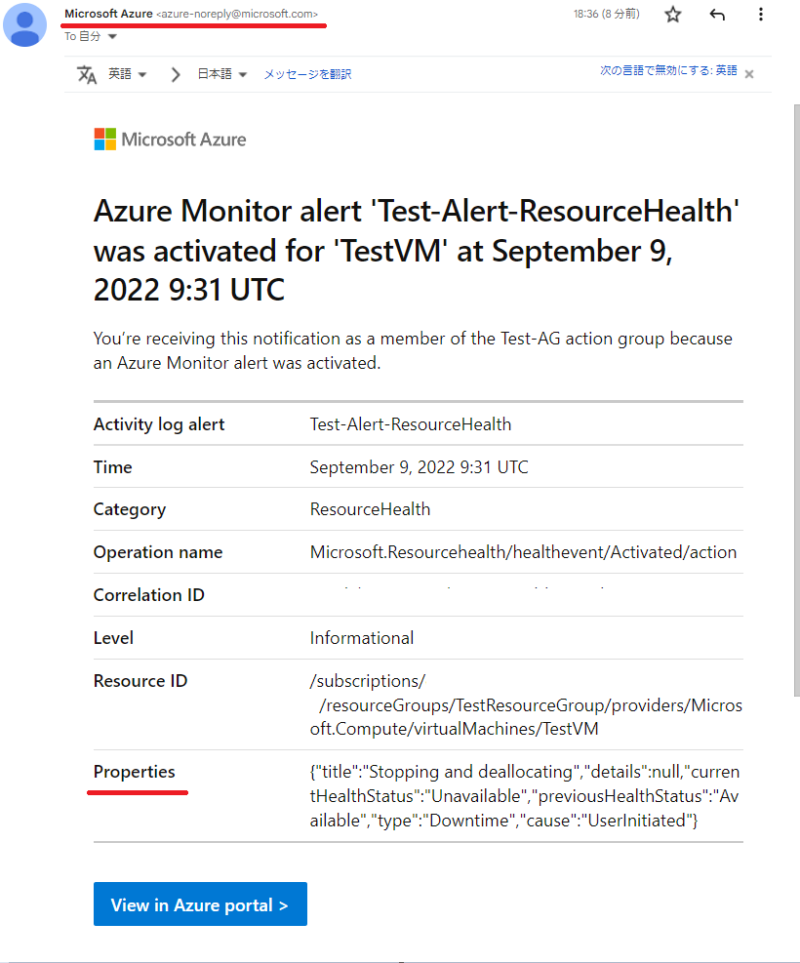
送信元については、差出人が「Microsoft Azure」であり、
メールアドレスは [azure-noreply@microsoft.com] という Azure からの通知でよく利用される送信元から来ていることが分かります。
また、メール本文の [Properties] の部分では「”cause”:”UserInitiated”」という部分でユーザ起因での事象だということが分かり、「“currentHealthStatus”:”Unavailable”,”previousHealthStatus”:”Available”」という部分でも上記で設定したステータスを検知してこの通知が来ていることが読み取れます。
やってみて分かったこと
最後に実際にメール通知まで飛ばしてみて分かったこともまとめておきます。
通知が来るまで少し時間がかかる(実測値:約5分)
仮想マシンを停止/再起動してからメール通知が届くまでの時間は、実測値で約5分でした。
※メール本文に検知時間が記載されており、メールの受信時間から計算しています。
10分くらいかかるのかなと思っていたので、「通知が来るまでまあまあ早いな」というのがやってみた感想でした。
リアルタイムを求める場合には適さないかもしれませんが、クラウド基盤ですし、
このくらいのタイムラグはしょうがないのかもしれません。
メールの件名を後から変更できない
メールを受信してから気づきましたが、届くメールの件名は後から変更できません。
そもそもメールの件名を指定することはできません。
そして、届くメールの件名には上記の通り「Azure Monitor Alert」と「アラート名」と「検知した時間」などが記載されますが、
アラート名は作成後に変更できないので、メールの件名も変更することができないということになります。
なのでこの部分は、どのようなメール通知が来るのかなど他の通知内容なども考慮してアラート名を考える必要があるなと感じました。

